
线性回归:从直觉到最小二乘法
线性回归(Linear Regression)是机器学习中最基础、也最常用的监督学习算法之一。它主要用于解决回归问题,也就是预测一个连续数值。
例如:
- 根据房屋面积预测房价。
- 根据学习时长预测考试分数。
- 根据广告投入预测销售额。
线性回归的核心思想很朴素:如果两个变量之间存在近似线性的关系,就可以用一条直线或者一个线性函数去描述这种关系,并用它来预测未知样本。
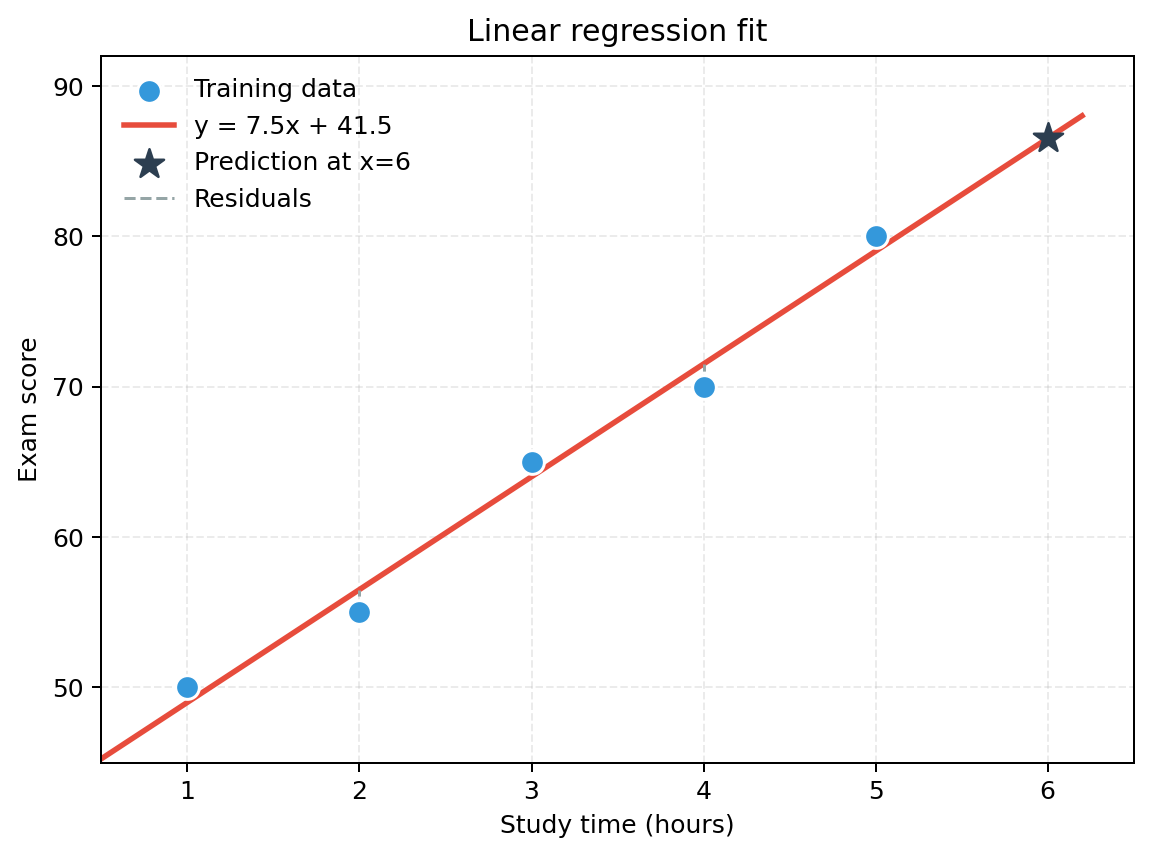
图中的蓝色点是训练数据,红色直线是拟合出的线性模型,灰色虚线表示预测值和真实值之间的误差。线性回归训练时,本质上就是在寻找一条让整体误差尽可能小的直线。
1. 线性回归的直觉
假设我们想根据学习时长预测考试分数,已有数据如下:
| 学习时长/小时 | 考试分数 |
|---|---|
| 1 | 50 |
| 2 | 55 |
| 3 | 65 |
| 4 | 70 |
| 5 | 80 |
把这些点画到坐标系中,可以发现:学习时间越长,考试分数通常越高。虽然这些点不一定完全落在同一条直线上,但整体趋势接近一条向上倾斜的直线。
线性回归要做的事情,就是找到一条尽可能贴近这些数据点的直线:
$$
\hat{y} = wx + b
$$
其中:
- $x$ 表示输入特征,比如学习时长。
- $\hat{y}$ 表示模型预测值,比如预测分数。
- $w$ 表示权重,也可以理解为直线的斜率。
- $b$ 表示偏置,也可以理解为直线在 $y$ 轴上的截距。
如果最终学到的模型是:
$$
\hat{y} = 7x + 43
$$
那么当一个学生学习 6 小时时,模型会预测:
$$
\hat{y} = 7 \times 6 + 43 = 85
$$
也就是说,预测考试分数为 85 分。
2. 一元线性回归
只有一个输入特征时,称为一元线性回归。模型形式为:
$$
\hat{y}^{(i)} = wx^{(i)} + b
$$
其中 $i$ 表示第 $i$ 个样本。
对于训练集:
$$
(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}), \dots, (x^{(m)}, y^{(m)})
$$
线性回归希望找到合适的 $w$ 和 $b$,让所有样本的预测值 $\hat{y}$ 尽可能接近真实值 $y$。
这里的“接近”需要一个明确的衡量标准,于是就引出了损失函数。
3. 损失函数
线性回归中最常用的损失函数是均方误差(Mean Squared Error,MSE):
$$
J(w, b) = \frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})^2
$$
因为:
$$
\hat{y}^{(i)} = wx^{(i)} + b
$$
所以也可以写成:
$$
J(w, b) = \frac{1}{m}\sum_{i=1}^{m}(wx^{(i)} + b - y^{(i)})^2
$$
这个公式的含义是:
- 对每个样本计算预测值和真实值之间的误差。
- 将误差平方,避免正负误差相互抵消。
- 对所有平方误差求平均。
线性回归的训练目标就是让这个损失函数尽可能小:
$$
\min_{w,b} J(w,b)
$$
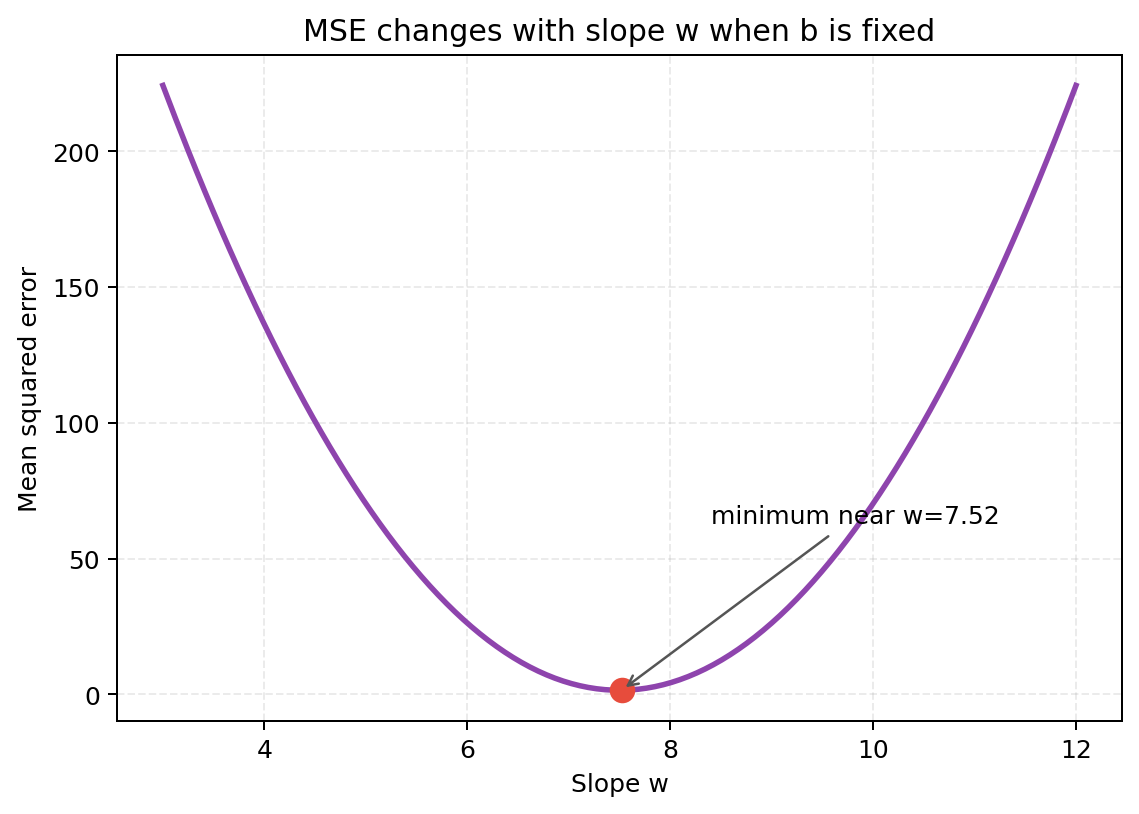
上图固定截距 $b=41.5$,只观察斜率 $w$ 变化时均方误差的变化。曲线最低的位置对应更合适的参数,这也解释了为什么训练模型可以理解为“寻找损失函数的最低点”。
4. 最小二乘法
对于一元线性回归,可以直接使用最小二乘法求出最优的 $w$ 和 $b$。
最优斜率 $w$ 的计算公式为:
$$
w = \frac{\sum_{i=1}^{m}(x^{(i)} - \bar{x})(y^{(i)} - \bar{y})}{\sum_{i=1}^{m}(x^{(i)} - \bar{x})^2}
$$
最优截距 $b$ 的计算公式为:
$$
b = \bar{y} - w\bar{x}
$$
其中:
- $\bar{x}$ 表示所有 $x$ 的平均值。
- $\bar{y}$ 表示所有 $y$ 的平均值。
从直觉上看,$w$ 描述的是 $x$ 增加时 $y$ 大约会增加多少;$b$ 则负责调整整条直线的上下位置。
5. 手工计算例子
仍然使用学习时长和考试分数的数据:
| 编号 | $x$ | $y$ |
|---|---|---|
| 1 | 1 | 50 |
| 2 | 2 | 55 |
| 3 | 3 | 65 |
| 4 | 4 | 70 |
| 5 | 5 | 80 |
先计算平均值:
$$
\bar{x} = \frac{1+2+3+4+5}{5} = 3
$$
$$
\bar{y} = \frac{50+55+65+70+80}{5} = 64
$$
接着计算 $w$:
| $x$ | $y$ | $x-\bar{x}$ | $y-\bar{y}$ | $(x-\bar{x})(y-\bar{y})$ | $(x-\bar{x})^2$ |
|---|---|---|---|---|---|
| 1 | 50 | -2 | -14 | 28 | 4 |
| 2 | 55 | -1 | -9 | 9 | 1 |
| 3 | 65 | 0 | 1 | 0 | 0 |
| 4 | 70 | 1 | 6 | 6 | 1 |
| 5 | 80 | 2 | 16 | 32 | 4 |
因此:
$$
w = \frac{28+9+0+6+32}{4+1+0+1+4} = \frac{75}{10} = 7.5
$$
再计算 $b$:
$$
b = 64 - 7.5 \times 3 = 41.5
$$
所以拟合出来的直线为:
$$
\hat{y} = 7.5x + 41.5
$$
当学习时间为 6 小时时:
$$
\hat{y} = 7.5 \times 6 + 41.5 = 86.5
$$
模型预测考试分数约为 86.5 分。
6. 多元线性回归
实际问题中,预测目标往往不只受一个因素影响。
例如房价可能同时受到这些因素影响:
- 房屋面积
- 房间数量
- 地理位置
- 房龄
- 楼层
如果有多个输入特征,就称为多元线性回归。模型形式为:
$$
\hat{y} = w_1x_1 + w_2x_2 + \dots + w_nx_n + b
$$
也可以写成向量形式:
$$
\hat{y} = \mathbf{w}^T\mathbf{x} + b
$$
其中:
- $\mathbf{x}$ 是特征向量。
- $\mathbf{w}$ 是权重向量。
- $b$ 是偏置。
多元线性回归的本质没有变化,仍然是在寻找一组参数,让预测值和真实值之间的误差尽可能小。
7. 梯度下降求解
当数据量较大、特征较多时,可以使用梯度下降来优化参数。
如果想系统理解梯度、学习率、收敛过程以及手写实现,可以先阅读:梯度下降法:机器学习如何一步步找到最优解。
梯度下降的核心思想是:先随机给 $w$ 和 $b$ 一个初始值,然后不断沿着损失函数下降最快的方向更新参数,直到损失足够小。
参数更新公式为:
$$
w := w - \alpha \frac{\partial J(w,b)}{\partial w}
$$
$$
b := b - \alpha \frac{\partial J(w,b)}{\partial b}
$$
其中 $\alpha$ 是学习率,用来控制每次更新参数的步长。
对于一元线性回归:
$$
\frac{\partial J(w,b)}{\partial w}
= \frac{2}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})x^{(i)}
$$
$$
\frac{\partial J(w,b)}{\partial b}
= \frac{2}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})
$$
学习率不能太大,也不能太小:
- 如果学习率太大,可能会越过最优点,导致损失震荡甚至发散。
- 如果学习率太小,收敛速度会很慢,需要训练很多轮。
8. Python 实现
8.1 使用最小二乘法手写实现
import numpy as np
x = np.array([1, 2, 3, 4, 5], dtype=float)
y = np.array([50, 55, 65, 70, 80], dtype=float)
# 对应模块:计算 x 的平均值,也就是所有输入特征的中心位置
x_mean = np.mean(x)
# 对应模块:计算 y 的平均值,也就是真实标签的中心位置
y_mean = np.mean(y)
# 对应模块:最小二乘法求斜率 w,表示 x 每增加 1,预测值大约增加多少
w = np.sum((x - x_mean) * (y - y_mean)) / np.sum((x - x_mean) ** 2)
# 对应模块:根据斜率和均值求截距 b,也就是直线和 y 轴的交点
b = y_mean - w * x_mean
print("w =", w)
print("b =", b)
new_x = 6
# 对应模块:线性回归预测,预测值 = 斜率 * 输入 + 截距
prediction = w * new_x + b
print("预测分数 =", prediction)输出结果大致为:
w = 7.5
b = 41.5
预测分数 = 86.58.2 使用梯度下降手写实现
最小二乘法可以直接算出解析解,而梯度下降则是通过不断更新参数来逼近最优解。
线性回归中,如果损失函数为:
$$
J(w,b)=\frac{1}{m}\sum_{i=1}^{m}(wx^{(i)}+b-y^{(i)})^2
$$
那么梯度为:
$$
\frac{\partial J}{\partial w}=\frac{2}{m}\sum_{i=1}^{m}(wx^{(i)}+b-y^{(i)})x^{(i)}
$$
$$
\frac{\partial J}{\partial b}=\frac{2}{m}\sum_{i=1}^{m}(wx^{(i)}+b-y^{(i)})
$$
对应代码如下:
import numpy as np
x = np.array([1, 2, 3, 4, 5], dtype=float)
y = np.array([50, 55, 65, 70, 80], dtype=float)
# 初始化参数
w = 0.0
b = 0.0
# 对应模块:学习率,控制每次参数更新走多大一步
learning_rate = 0.01
# 训练轮数
epochs = 2000
# 对应模块:样本数量,用来把总误差和总梯度转成平均值
m = len(x)
for epoch in range(epochs):
# 对应模块:线性回归预测,预测值 = 斜率 * 输入 + 截距
y_pred = w * x + b
# 对应模块:预测误差,误差 = 预测值 - 真实值
error = y_pred - y
# 对应模块:均方误差损失,把每个样本的误差平方后再求平均
loss = np.mean(error ** 2)
# 对应模块:斜率 w 的梯度,表示当前 w 应该往哪个方向调整
dw = (2 / m) * np.sum(error * x)
# 对应模块:截距 b 的梯度,表示当前 b 应该往哪个方向调整
db = (2 / m) * np.sum(error)
# 对应模块:梯度下降更新斜率,新 w = 旧 w - 学习率 * w 的梯度
w = w - learning_rate * dw
# 对应模块:梯度下降更新截距,新 b = 旧 b - 学习率 * b 的梯度
b = b - learning_rate * db
if epoch % 400 == 0:
print(f"epoch={epoch}, loss={loss:.4f}, w={w:.4f}, b={b:.4f}")
new_x = 6
# 对应模块:线性回归预测,预测值 = 斜率 * 输入 + 截距
prediction = w * new_x + b
print("预测分数 =", prediction)这段代码可以帮助我们把“公式”和“训练过程”对应起来:每一轮都先计算预测值和误差,再根据梯度更新 $w$ 和 $b$。
8.3 使用 scikit-learn 实现
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1], [2], [3], [4], [5]], dtype=float)
y = np.array([50, 55, 65, 70, 80], dtype=float)
model = LinearRegression()
# 对应模块:训练线性回归模型,内部会求出斜率 w 和截距 b
model.fit(X, y)
# 对应模块:模型学到的斜率 w
print("w =", model.coef_[0])
# 对应模块:模型学到的截距 b
print("b =", model.intercept_)
# 对应模块:使用训练好的直线进行预测
prediction = model.predict([[6]])
print("预测分数 =", prediction[0])在 scikit-learn 中,输入特征 $X$ 通常需要是二维数组,即使只有一个特征,也要写成 [[1], [2], [3]] 这样的形式。
9. 模型评估指标
线性回归属于回归模型,常用评估指标包括 MAE、MSE、RMSE 和 $R^2$。
9.1 MAE
MAE(Mean Absolute Error,平均绝对误差):
$$
MAE = \frac{1}{m}\sum_{i=1}^{m}|\hat{y}^{(i)} - y^{(i)}|
$$
MAE 表示预测值和真实值平均相差多少,单位和原始标签一致,因此比较容易理解。
9.2 MSE
MSE(Mean Squared Error,均方误差):
$$
MSE = \frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})^2
$$
MSE 会放大较大的误差,因此对异常值更敏感。
9.3 RMSE
RMSE(Root Mean Squared Error,均方根误差):
$$
RMSE = \sqrt{\frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})^2}
$$
RMSE 对 MSE 开平方后,单位重新回到原始标签的单位。
9.4 $R^2$
$R^2$ 又叫决定系数,用来衡量模型对数据变化的解释能力:
$$
R^2 = 1 - \frac{\sum_{i=1}^{m}(y^{(i)} - \hat{y}^{(i)})^2}{\sum_{i=1}^{m}(y^{(i)} - \bar{y})^2}
$$
$R^2$ 越接近 1,说明模型拟合效果越好;如果 $R^2$ 接近 0,说明模型效果可能和直接预测平均值差不多。
10. 线性回归的优缺点
10.1 优点
- 模型简单,容易理解和实现。
- 训练速度快,适合作为回归任务的 baseline。
- 参数具有一定可解释性,可以观察每个特征对预测结果的影响。
- 对线性关系明显的数据效果很好。
10.2 缺点
- 表达能力有限,难以拟合复杂的非线性关系。
- 对异常值比较敏感,极端样本可能明显影响拟合结果。
- 特征之间存在强相关性时,参数解释可能变得不稳定。
- 假设特征和目标值之间近似线性,如果这个假设不成立,效果会比较差。
11. 实际使用时的注意点
11.1 观察数据是否接近线性关系
线性回归适合处理接近线性关系的数据。如果特征和目标之间明显是曲线关系,可以考虑加入多项式特征,或者使用决策树、随机森林、梯度提升树等非线性模型。
11.2 注意异常值
由于线性回归通常使用平方误差作为损失函数,异常值会被放大。训练前可以先画散点图、箱线图,或者使用统计方法检查异常样本。
11.3 做好特征处理
对于多元线性回归,特征尺度差异过大时,虽然普通最小二乘法仍然能求解,但在使用梯度下降时会影响收敛速度。因此常见做法是对特征进行标准化:
$$
z = \frac{x - \mu}{\sigma}
$$
其中 $\mu$ 是均值,$\sigma$ 是标准差。
11.4 避免只看训练集误差
如果模型只在训练集上表现好,但在测试集上表现差,说明模型泛化能力不足。更合理的做法是将数据划分为训练集和测试集,再使用测试集评估模型效果。
12. 总结
线性回归的核心可以概括为一句话:用一个线性函数去拟合输入特征和连续目标值之间的关系。
它的关键步骤是:
- 假设模型形式,例如 $\hat{y} = wx + b$。
- 定义损失函数,例如均方误差。
- 通过最小二乘法或梯度下降求出最优参数。
- 使用 MAE、MSE、RMSE、$R^2$ 等指标评估模型。
虽然线性回归看起来简单,但它包含了机器学习中很多重要思想:模型假设、损失函数、参数优化、泛化能力和特征处理。理解线性回归之后,再学习逻辑回归、神经网络、支持向量机等模型时,会更容易抓住其中的共同脉络。