
K 近邻算法:KNN(K-Nearest Neighbors)
KNN(K-Nearest Neighbors,K 近邻)是一种非常直观的监督学习算法:一个样本属于什么类别,可以参考它在特征空间中最近的 $K$ 个邻居。
在分类任务中,KNN 通常采用“多数投票”:最近的 $K$ 个样本里哪个类别最多,就预测为哪个类别;在回归任务中,KNN 通常取最近 $K$ 个样本标签值的平均值或加权平均值。
1. KNN 的直觉
可以把 KNN 想象成“向邻居打听答案”。
假设小区里新搬来一户人家,你想判断他们更像“高收入家庭”还是“普通收入家庭”。最直接的方式,是观察离他们最近的几户邻居:如果最近的 5 户里有 3 户都是高收入家庭,那么你可能会猜测这户新邻居也更接近高收入家庭。
机器学习里的 KNN 做的是类似的事情:
- 输入:一个尚未标记类别的新样本。
- 过程:在训练集中找到距离它最近的 $K$ 个已知样本。
- 输出:分类时进行多数投票,回归时进行平均或加权平均。
KNN 本质上没有显式的训练过程,它把训练数据保存下来,预测时再计算新样本与训练样本之间的距离。因此它也被称为惰性学习(Lazy Learning)。
2. 数学原理
KNN 要解决两个核心问题:
- 如何定义“近”?也就是距离度量。
- 找到邻居后如何做决策?也就是分类或回归规则。
2.1 距离度量
假设两个 $n$ 维样本分别为:
$$
\mathbf{x} = (x_1, x_2, \dots, x_n)
$$
$$
\mathbf{y} = (y_1, y_2, \dots, y_n)
$$
不同的距离函数会影响 KNN 对“相似”的判断。
欧氏距离
欧氏距离是最常见的距离度量,可以理解为多维空间中的直线距离:
$$
d(\mathbf{x}, \mathbf{y}) = \sqrt{\sum_{i=1}^{n}(x_i - y_i)^2}
$$
二维空间中,它就是两点之间的几何距离。
曼哈顿距离
曼哈顿距离可以理解为在网格道路中行走时的距离,只能横向或纵向移动:
$$
d(\mathbf{x}, \mathbf{y}) = \sum_{i=1}^{n}|x_i - y_i|
$$
闵可夫斯基距离
闵可夫斯基距离是欧氏距离和曼哈顿距离的推广:
$$
d(\mathbf{x}, \mathbf{y}) =
\left(\sum_{i=1}^{n}|x_i - y_i|^p\right)^{\frac{1}{p}}
$$
当 $p=1$ 时,它等价于曼哈顿距离;当 $p=2$ 时,它等价于欧氏距离。
2.2 为什么要做特征缩放
KNN 对特征尺度非常敏感。
假设一个样本有两个特征:年收入和年龄。年收入的范围可能是 $0 \sim 100000$,年龄的范围可能是 $0 \sim 100$。如果直接计算欧氏距离,年收入会主导距离结果,年龄的影响几乎被淹没。
因此,在使用 KNN 前通常要先进行标准化或归一化:
$$
z = \frac{x - \mu}{\sigma}
$$
其中 $\mu$ 是均值,$\sigma$ 是标准差。标准化后,不同特征会处于更可比较的尺度上。
3. 手工计算例子:水果分类
假设我们用两个特征判断水果类别:
- 甜度 $x_1$
- 脆度 $x_2$
已有训练数据如下:
| 编号 | 类别 | 甜度 $x_1$ | 脆度 $x_2$ | 坐标 |
|---|---|---|---|---|
| A | 苹果 | 8 | 7 | $(8, 7)$ |
| B | 苹果 | 7 | 8 | $(7, 8)$ |
| C | 梨 | 2 | 4 | $(2, 4)$ |
| D | 梨 | 3 | 3 | $(3, 3)$ |
现在有一个未知水果 $X=(4,5)$,设 $K=3$,判断它是苹果还是梨。
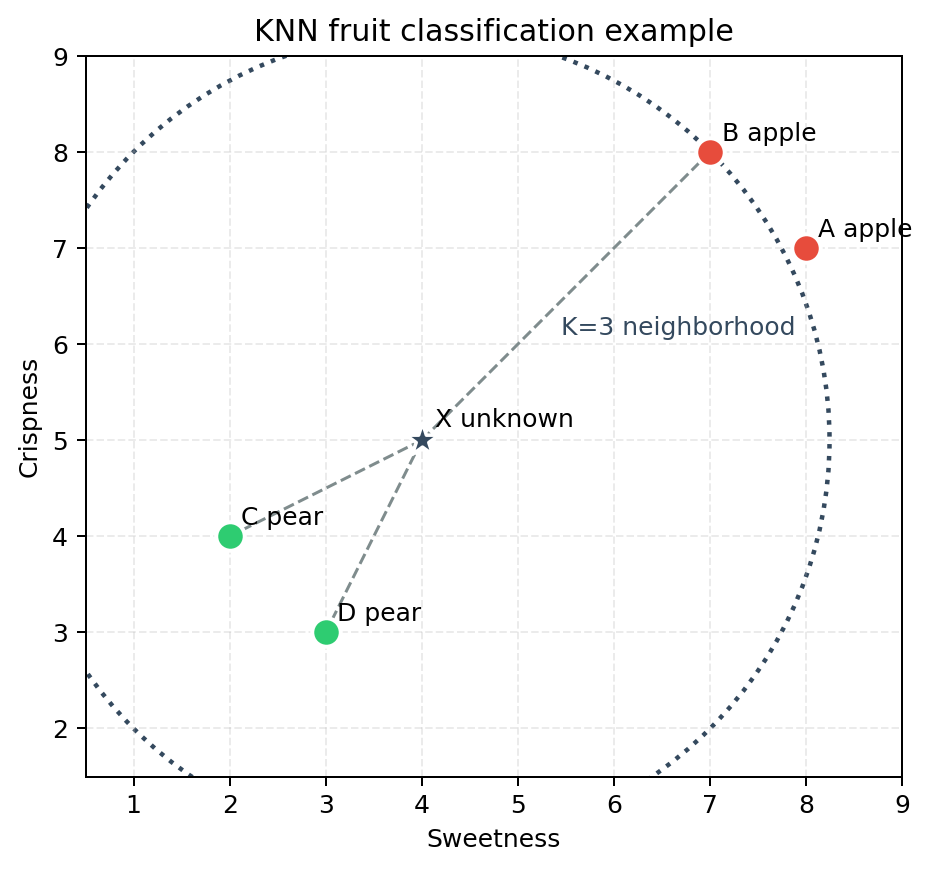
图中的星形点表示未知水果,虚线连接的是它最近的 3 个邻居。通过这张图可以更直观地看到:KNN 并不是提前学出一个公式,而是在预测时临时寻找附近样本,再根据邻居类别做判断。
3.1 计算距离
使用欧氏距离:
$$
d(X,A)=\sqrt{(4-8)^2+(5-7)^2}=\sqrt{20}\approx4.47
$$
$$
d(X,B)=\sqrt{(4-7)^2+(5-8)^2}=\sqrt{18}\approx4.24
$$
$$
d(X,C)=\sqrt{(4-2)^2+(5-4)^2}=\sqrt{5}\approx2.24
$$
$$
d(X,D)=\sqrt{(4-3)^2+(5-3)^2}=\sqrt{5}\approx2.24
$$
按距离从小到大排序:
| 排名 | 邻居 | 类别 | 距离 |
|---|---|---|---|
| 1 | C | 梨 | $2.24$ |
| 2 | D | 梨 | $2.24$ |
| 3 | B | 苹果 | $4.24$ |
| 4 | A | 苹果 | $4.47$ |
因为 $K=3$,最近的 3 个邻居是 C、D、B。其中梨有 2 票,苹果有 1 票,所以 KNN 会预测:
$$
\hat{y}=\text{梨}
$$
4. 决策规则
4.1 分类任务
分类任务中最常见的是多数投票:
$$
\hat{y}=\arg\max_{c}\sum_{i \in N_K(x)} I(y_i=c)
$$
其中 $N_K(x)$ 表示样本 $x$ 的 $K$ 个最近邻,$I(\cdot)$ 是指示函数。
如果希望离得更近的邻居拥有更高权重,可以使用距离加权投票:
$$
w_i=\frac{1}{d(x,x_i)+\epsilon}
$$
这里 $\epsilon$ 是一个很小的正数,用来避免距离为 0 时分母出错。
4.2 回归任务
回归任务中,KNN 可以取最近邻标签的平均值:
$$
\hat{y}=\frac{1}{K}\sum_{i \in N_K(x)}y_i
$$
也可以使用距离加权平均:
$$
\hat{y}=\frac{\sum_{i \in N_K(x)} w_i y_i}{\sum_{i \in N_K(x)}w_i}
$$
5. 如何选择 K 值
$K$ 是 KNN 中最重要的超参数之一。
- $K$ 太小:模型会过于敏感,容易受到噪声点影响,训练集表现很好但泛化能力较差,这通常对应过拟合。
- $K$ 太大:模型会参考太多远处样本,决策边界过于平滑,难以捕捉局部结构,这通常对应欠拟合。
在二分类任务中,通常会优先尝试奇数 $K$,例如 $K=3,5,7$,这样可以减少平票情况。但在多分类任务中,即使 $K$ 是奇数也可能平票,此时可以使用距离加权、降低 $K$ 或制定固定的平票处理规则。
实践中常用交叉验证选择合适的 $K$:
$$
K^* = \arg\min_K \text{CVError}(K)
$$
6. Python 实战:从手写 KNN 到 sklearn
理解 KNN 时,最好不要一开始就只看 sklearn。因为 KNN 的核心非常适合手写:计算距离、排序、取最近的 $K$ 个邻居、投票。
下面先根据公式手写一个最小版本,再使用 sklearn 构造二维数据集,观察不同 $K$ 值下的决策边界。
安装依赖:
pip install scikit-learn numpy matplotlib6.1 根据公式手写 KNN
以 KNN 分类问题为例,核心公式可以理解为:
$$
\hat{y} = \operatorname{mode}(y_i \mid x_i \in N_K(x))
$$
其中 $N_K(x)$ 表示距离待预测样本 $x$ 最近的 $K$ 个训练样本,$\operatorname{mode}$ 表示取出现次数最多的类别。
下面用 Python 手写一个 KNN 分类器:
import numpy as np
from collections import Counter
class SimpleKNNClassifier:
def __init__(self, k=3):
# k 表示预测时参考最近的几个邻居
self.k = k
def fit(self, X, y):
# KNN 没有显式的训练过程,本质是把训练数据保存下来
self.X_train = np.asarray(X, dtype=float)
self.y_train = np.asarray(y)
return self
def _euclidean_distance(self, x1, x2):
# 欧氏距离公式:sqrt(sum((x1_j - x2_j)^2))
return np.sqrt(np.sum((x1 - x2) ** 2))
def _predict_one(self, x):
distances = []
# 计算待预测样本与每个训练样本之间的距离
for x_train in self.X_train:
distances.append(self._euclidean_distance(x, x_train))
# argsort 会返回从小到大排序后的下标,前 k 个就是最近的 k 个邻居
nearest_indices = np.argsort(distances)[:self.k]
# 根据最近邻的下标取出对应类别
nearest_labels = self.y_train[nearest_indices]
# Counter 统计每个类别出现次数,票数最多的类别就是预测结果
vote_result = Counter(nearest_labels).most_common(1)
return vote_result[0][0]
def predict(self, X):
# 对多个样本逐个预测
X = np.asarray(X, dtype=float)
return np.array([self._predict_one(x) for x in X])
# 训练数据:两个特征分别表示甜度和脆度
X_train = np.array([
[8, 7], # 苹果
[7, 8], # 苹果
[2, 4], # 梨
[3, 3], # 梨
])
y_train = np.array(["苹果", "苹果", "梨", "梨"])
# 待预测水果
X_test = np.array([[4, 5]])
model = SimpleKNNClassifier(k=3)
model.fit(X_train, y_train)
prediction = model.predict(X_test)
print(prediction)输出结果为:
['梨']这个手写版本体现了 KNN 的本质:
fit阶段并没有真正训练参数,只是保存训练集。predict阶段才计算距离。- 最终结果来自最近 $K$ 个邻居的多数投票。
如果想加入距离加权,也可以把“每个邻居一票”改成“距离越近票越重”。例如权重可以设为:
$$
w_i = \frac{1}{d_i + \varepsilon}
$$
这里加上很小的 $\varepsilon$,是为了避免距离为 0 时出现除零错误。
6.2 使用 sklearn 训练 KNN 模型并观察决策边界
手写代码适合理解原理,但真实项目中通常会使用 sklearn。下面代码使用 scikit-learn 构造一个二维数据集,并对比 $K=1$、$K=5$、$K=15$ 时的决策边界。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_moons
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# 构造一个非线性二分类数据集,方便观察 KNN 的决策边界
X, y = make_moons(n_samples=200, noise=0.3, random_state=42)
# KNN 对特征尺度非常敏感,所以先进行标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 生成二维网格,用来画出模型在每个区域的预测类别
h = 0.02
x_min, x_max = X_scaled[:, 0].min() - 0.5, X_scaled[:, 0].max() + 0.5
y_min, y_max = X_scaled[:, 1].min() - 0.5, X_scaled[:, 1].max() + 0.5
xx, yy = np.meshgrid(
np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h),
)
# 分别观察小 K、中等 K、大 K 对决策边界的影响
k_values = [1, 5, 15]
cmap_light = ListedColormap(["#FEE2E2", "#DBEAFE"])
cmap_bold = ListedColormap(["#DC2626", "#2563EB"])
plt.figure(figsize=(15, 4.5))
for i, k in enumerate(k_values, start=1):
# 创建 KNN 分类器,n_neighbors 就是 K 值
clf = KNeighborsClassifier(n_neighbors=k)
# KNN 的 fit 主要是保存训练样本,预测时再查找最近邻
clf.fit(X_scaled, y)
# 对网格上的每个点预测类别,用于绘制背景决策区域
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.subplot(1, 3, i)
plt.pcolormesh(xx, yy, Z, cmap=cmap_light, shading="auto")
# 绘制原始样本点,颜色表示真实类别
plt.scatter(
X_scaled[:, 0],
X_scaled[:, 1],
c=y,
cmap=cmap_bold,
edgecolors="k",
s=36,
)
plt.title(f"KNN Decision Boundary (K={k})")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.tight_layout()
plt.show()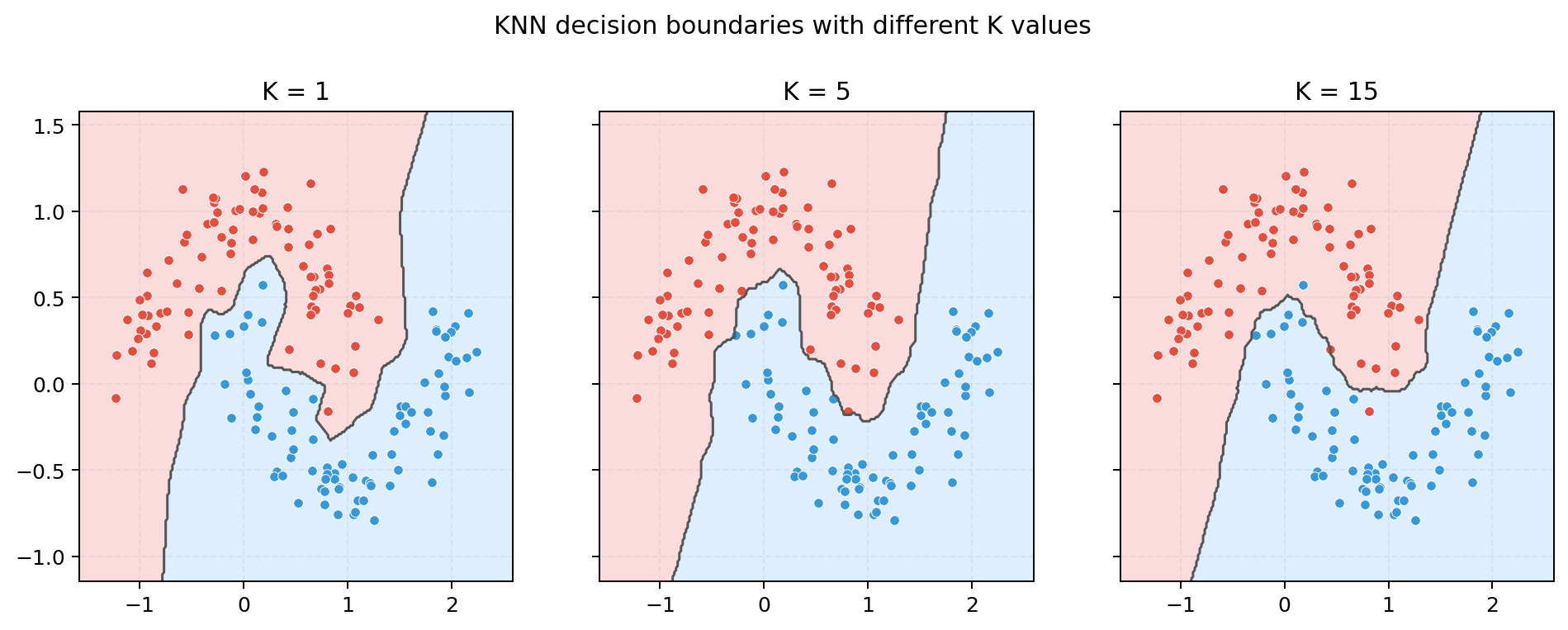
从图中可以看到:
- $K=1$ 时,决策边界非常曲折,模型对局部噪声非常敏感。
- $K=5$ 时,边界相对平滑,同时还能保留数据的局部结构。
- $K=15$ 时,边界进一步变平滑,如果继续增大 $K$,模型可能出现欠拟合。
7. KNN 的优缺点
优点
- 简单直观,容易理解和实现。
- 不需要显式训练过程,适合做快速基线模型。
- 天然支持多分类任务。
- 对非线性边界有一定表达能力,因为决策边界由局部邻居决定。
缺点
- 预测阶段计算成本高,每次预测都需要计算新样本与大量训练样本的距离。
- 内存消耗较大,需要保存训练集。
- 对特征尺度敏感,通常必须先做特征缩放。
- 对高维数据不友好,容易受到维度灾难影响。
- 对类别不平衡较敏感,多数类样本可能在邻域中占优势。
8. 实践建议
使用 KNN 时,可以按下面的顺序思考:
- 先进行数据清洗,处理缺失值和异常值。
- 对连续特征做标准化或归一化。
- 用交叉验证选择 $K$。
- 视情况选择距离度量,例如欧氏距离、曼哈顿距离或余弦距离。
- 如果数据规模较大,可以考虑 KD-Tree、Ball Tree 或近似最近邻搜索。
- 如果类别不平衡,可以尝试距离加权或重采样方法。
9. 总结
KNN 的思想非常朴素:相似的样本往往拥有相似的标签。它没有复杂的训练过程,却能在许多小规模、低维、结构清晰的数据集上取得不错效果。
要用好 KNN,最重要的是记住三点:
- 特征缩放几乎是必需的。
- $K$ 值需要通过验证集或交叉验证选择。
- 数据维度和数据规模会直接影响 KNN 的效果与速度。
因此,KNN 很适合作为入门算法和基线模型;但在大规模、高维度或实时预测场景中,需要谨慎使用。